What is Reverse ETL?
Ever imagine what we can do with the right context? Communicating with context dramatically improves the customer’s experience with your product. If only we can access the right data at the right moment. How hard can it be, right?
Companies collect heaps of data directly and indirectly from their customers every day. This data ideally should help the stakeholders make business decisions. Reverse ETL helps us break data silos and leverage data by pushing it to SaaS applications where it makes more sense.
Before we explore what reverse ETL is, let’s look at how it all started.
A Brief Background
Data integration has always been the goal, we wanted a centralized storage and view of data to understand our users and predict their needs better. Collecting data for storage and analysis started in the 1970s. The early adopters Extracted data from limited sources, Transformed it into a convenient format, and Loaded it into data warehouses. The traditional ETL tools processed low volumes of data back in the day. With the advent of the cloud our storage and processing needs also grew. Though this led to the rise of modern data integration infrastructure and tools, modern ETL tools are still the dominant choice.
The data you collected from first-party sources like your app, your partner tools and websites, and third-party data sources are consolidated to make the data warehouse your single source of truth. But, the data is still siloed. To be able to leverage the data and make informed decisions, we need to operationalize it. This is where reverse ETL comes into the picture. As the name suggests it starts with the data warehouse and makes the transformed data available for frontend teams through the SaaS applications they use as part of their daily workflow.
Reverse ETL takes the data from your system of record — the data warehouse like Snowflake and BigQuery to your operational systems — the CRMs like Salesforce, marketing automation platforms like Inflection.io, support systems, and other SaaS tools, making it actionable. In other words, reverse ETL assists in operationalizing data.
Why Reverse ETL Now?
We need Reverse ETL to solve the last mile problem of data analytics called operational analytics. Operational analytics is about turning insights into action, automatically. All the data ingested and analyzed in the data warehouses is only actually useful when your go-to-market teams can access the insights through tools they live in (Salesforce, Zendesk, Marketo, etc.) for making important decisions. Reverse ETL helps make this possible to some degree.

If you are a product-led growth company, you have a large volume of free users and potential customers. Every action you take from qualifying leads to upselling/cross-selling, and everything in between relies on marketing, firmographic, account, and product data.
The use cases reverse ETL offers to PLG (also non-PLG) companies are virtually limitless. Your GTM teams can get a better understanding of your Ideal Customer Profile (ICP) with behavioral data sourced from your product, website, and also 3rd party sources like social media. The data fields set up in the business applications you use every day get updated with data pushed from the data warehouse.
Reverse ETL makes it easy to bring siloed data into applications where it makes more sense to act on the insights. There are also some considerations to have with reverse ETL.
Considerations of Reverse ETL
So, we get the right data from all the right sources at the right time, so we make the best decisions to provide the best customer experience. If only we lived in a perfect, perfect world!
1. The Data Mapping Problem
When your data warehouse becomes your single source of truth, you have data points collected and stored from various sources. You can leverage this data when you can push the relevant information to your SaaS applications.
Creating corresponding custom fields in your application CRMs to match hundreds of product events is a huge task. You need to sacrifice resources to get all the product events created and pushed to your Salesforces, Marketos, and Zendesks of the world to be able to leverage the data. Talking about the volume of data in the pipelines brings me to the next limitation.
2. The Code Disadvantage
To implement reverse ETL, you either have to have access to data and engineering resources or you need to write SQL code yourself. Even with good knowledge of SQL, you still need to connect every data field your GTM teams use to the right table entry. You’d end up writing SQL queries for each and every data point to be able to use it.
3. You Might Be Operating Off Of Old Data
Reverse ETL was devised traditionally for batch processing to aid data analysis. These tools pull from a data warehouse which in turn might be getting the data infrequently in batches, like through a nightly data sync. This means you are operating off of old data, so if you’re looking to use the data for near real-time use cases you might want to think twice.
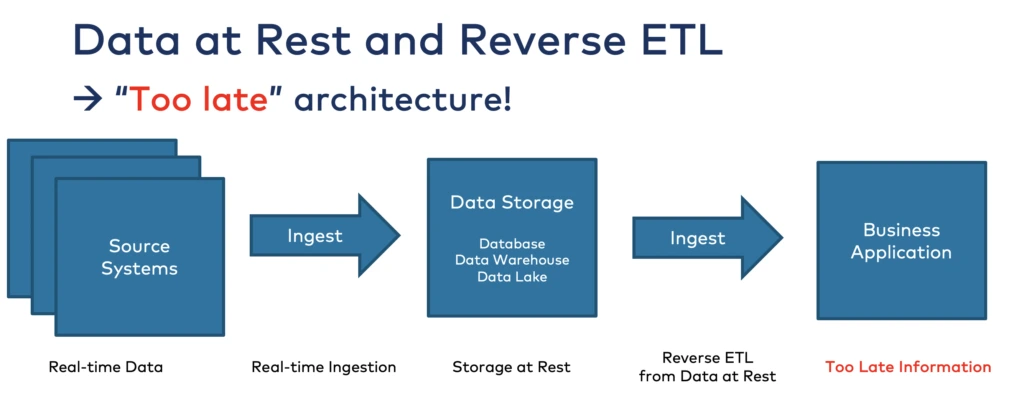
Source: Kai Waehner
If you have a product-led growth motion in place, to automate your emails or in-product notifications triggered by customer activity, reverse ETL can be a great way to get started if you have few users, have just a few product events you want to track, and you are ok with some of the other considerations. . The data does not get delivered to your CRM in not real-time through reverse ETL. Triggering your campaigns based on old data can easily hurt your purpose.
Wrapping It Up
Reverse ETL tools come with a promise of democratizing data across the organization - and it can definitely do that for some scenarios. Consider your use cases and as you are building your modern data stack, for some pieces - like marketing automation where your team needs access to ALL events and needs the most updated version - it could be better to have that connect directly into the product analytics feed.
Inflection is a customer communication platform built for the modern data stack. Request a demo to see Inflection in action.
